Here’s a short guide on how to run CUDA code on Kaggle notebooks. This seems to be the cheapest setup to do so without acquiring actual Nvidia hardware – thanks Kaggle.
- Ensure your environment has access to a GPU
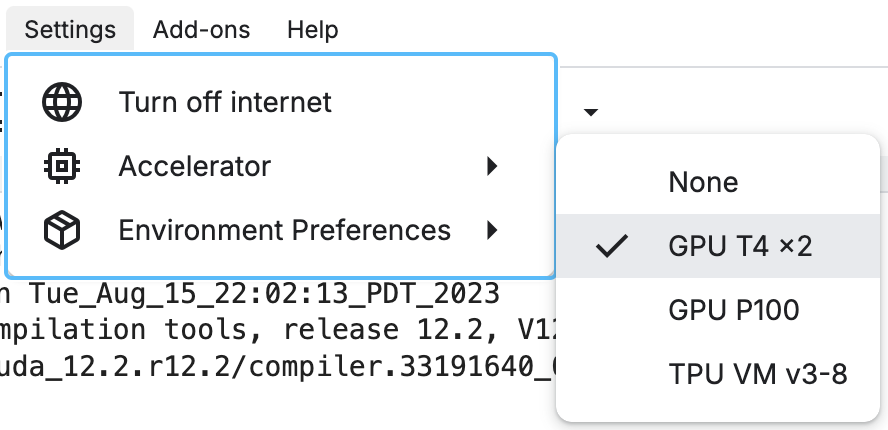
- Use Nvidia SMI to verify a Nvidia GPU is correctly configured.
!nvidia-smi !nvcc --version - Install nvcc4jupyter into the environment.
!pip install nvcc4jupyter %load_ext nvcc4jupyter - Run your cuda code prefixed with
%%cuda!
Sample Code
Here’s some sample code from the first chapter of PMPP to test your setup, along with the expected output.
This code creates a vector addition kernel (basically the hello world of CUDA), allocating and filling memory on the host (CPU), allocating memory on the device (GPU), and then moving the data onto the GPU. Next, we call the kernel with the block and thread numbers. Finally, we move the device output onto the host and free all used memory.
%%cuda
#include <iostream>
__global__
void vecAddKernel(float* A, float* B, float* C, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
C[i] = B[i] + A[i];
}
}
void vecAdd(float* A_h, float* B_h, float* C_h, int n) {
int size = sizeof(float) * n;
float *A_d, *B_d, *C_d;
cudaMalloc((void**) &A_d, size);
cudaMalloc((void**) &B_d, size);
cudaMalloc((void**) &C_d, size);
cudaMemcpy(A_d, A_h, size, cudaMemcpyHostToDevice);
cudaMemcpy(B_d, B_h, size, cudaMemcpyHostToDevice);
vecAddKernel<<<ceil(n/256.0), 256>>>(A_d, B_d, C_d, n);
cudaMemcpy(C_h, C_d, size, cudaMemcpyDeviceToHost);
cudaFree(A_d);
cudaFree(B_d);
cudaFree(C_d);
}
int main() {
int n = 9;
float* A_h = new float[n];
float* B_h = new float[n];
float* C_h = new float[n];
for(int i = 0; i < n; i++) {
A_h[i] = i;
B_h[i] = i * 2;
std::cout << "Initial A[" << i << "]=" << A_h[i] << ", B[" << i << "]=" << B_h[i] << std::endl;
}
vecAdd(A_h, B_h, C_h, n);
std::cout << "\nResults:\n";
for(int i = 0; i < n; i++) {
std::cout << A_h[i] << " + " << B_h[i] << " = " << C_h[i] << std::endl;
}
delete[] A_h;
delete[] B_h;
delete[] C_h;
return 0;
}
Correct output
Initial A[0]=0, B[0]=0
Initial A[1]=1, B[1]=2
Initial A[2]=2, B[2]=4
Initial A[3]=3, B[3]=6
Initial A[4]=4, B[4]=8
Initial A[5]=5, B[5]=10
Initial A[6]=6, B[6]=12
Initial A[7]=7, B[7]=14
Initial A[8]=8, B[8]=16
Results:
0 + 0 = 0
1 + 2 = 3
2 + 4 = 6
3 + 6 = 9
4 + 8 = 12
5 + 10 = 15
6 + 12 = 18
7 + 14 = 21
8 + 16 = 24
